(I did not check Twixtbot, because my Twixtbot is broken. My PySimpleGUI license has expired, and they don't offer the free hobbyist license anymore. I'd have to pay $99, and I'm thinking, you know, the way things are going, soon we'll just vibe code our own Twixtbots....)
On
2025-12-02 at 02:03,
Peyrol
said:
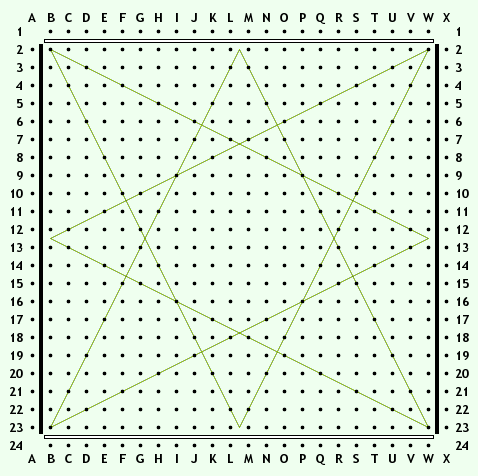
It looks like a different move order of the same variation after |27.h1628.f1429.l17black's "corresponding move" is 30.n17 then for example 31.j1432.j1633.k1634.k18 Maybe I missed something. My bot isn't working either. Maybe I could ask Grok.
Why Grok? As I understand it, the best coding LLMs are Gemini and Claude. Gemini even has a free coding IDE called Antigravity. I haven't tried it.
On
2025-12-03 at 14:50,
Peyrol
said:
Maybe Grok could analyze a Twixt position directly, without generating code.
On
2025-12-03 at 17:04,
Alan Hensel
said:
I doubt it. LLMs fundamentally process 1-dimensional streams of tokens. Even if they are "multimodal" and can interpret and generate images, they have limited ability to reason visually. People have noted this about Chess. It gets 4 or 5 moves in and starts suggesting poor or illegal moves. I'm sure that extends to any board game. This is just part of a larger missing piece of the current state of AI: "world models", the ability to come up with a simulation that can accurately predict the outcome of physical events, bespoke to a query.
On
2025-12-04 at 03:40,
MCx
said:
Comments from an AI (ChatGPT): (via MisterCat): Your point about LLMs lacking visual world models is well taken. They can discuss Twixt positions if fed structured input or a rendered board, but they don't "see" spatial relationships the way a true engine—or human—does. They can fake insight, but not simulate. For now, they’re more useful as commentators than as players.
In terms of architecture, even multimodal LLMs like Gemini or GPT-4V parse images as flattened spatial grids, not persistent object graphs. So while they can extract features, they don’t maintain the kind of dynamic, spatially-updating state that a Twixt engine—or a chess engine—relies on for position evaluation.
On
2025-12-09 at 21:46,
bob440
said:
maybe I'm missing something, but rather than re-inventing all of twixtbot, isn't (ahem} "all" that is needed is a non-python GUI on top of the twixtbot code -- not by me, though, I never learned GUIs -- I was a kernel device driver guy
On
2025-12-10 at 02:20,
Alan Hensel
said:
Hi Bob. As a front-end developer, I'm very familiar with this "let's just rewrite the front end in a whole new framework or technology... hey, what's taking you guys so long?"
I may be more likely to wrongly assume the back end is easy.
It was just a flip comment, not a well-researched engineering recommendation. I could be totally wrong. I've never used Leela Zero, so I don't know how hard it is to set it up, or teach it a game, or how long the training takes. I have no plans to work on it. What I think is that what little I've vibe coded leads me to believe these AIs, such as they are today, are more comfortable with starting from scratch than working in an existing codebase. But if anyone decides to work on it, they should make that decision for themselves.
On
2025-12-10 at 22:31,
bob440
said:
well, I do hope you noticed (ahem) "all" which was intended to convey that I realize it is no small task
On
2025-12-11 at 01:00,
Alan Hensel
said:
Okay, yes.
And this may be more about the future than the present, but the point of vibe coding is to make programming tasks small.
My comment was meant to invoke the idea of prompting for a Twixtbot, wait for it to train up, and there it is. I don't know how many prompts this would take today, but someday, I don't see any reason why it shouldn't be one.



(I did not check Twixtbot, because my Twixtbot is broken. My PySimpleGUI license has expired, and they don't offer the free hobbyist license anymore. I'd have to pay $99, and I'm thinking, you know, the way things are going, soon we'll just vibe code our own Twixtbots....)
Why Grok? As I understand it, the best coding LLMs are Gemini and Claude. Gemini even has a free coding IDE called Antigravity. I haven't tried it.
Your point about LLMs lacking visual world models is well taken. They can discuss Twixt positions if fed structured input or a rendered board, but they don't "see" spatial relationships the way a true engine—or human—does. They can fake insight, but not simulate. For now, they’re more useful as commentators than as players.
In terms of architecture, even multimodal LLMs like Gemini or GPT-4V parse images as flattened spatial grids, not persistent object graphs. So while they can extract features, they don’t maintain the kind of dynamic, spatially-updating state that a Twixt engine—or a chess engine—relies on for position evaluation.
I may be more likely to wrongly assume the back end is easy.
It was just a flip comment, not a well-researched engineering recommendation. I could be totally wrong. I've never used Leela Zero, so I don't know how hard it is to set it up, or teach it a game, or how long the training takes. I have no plans to work on it. What I think is that what little I've vibe coded leads me to believe these AIs, such as they are today, are more comfortable with starting from scratch than working in an existing codebase. But if anyone decides to work on it, they should make that decision for themselves.
And this may be more about the future than the present, but the point of vibe coding is to make programming tasks small.
My comment was meant to invoke the idea of prompting for a Twixtbot, wait for it to train up, and there it is. I don't know how many prompts this would take today, but someday, I don't see any reason why it shouldn't be one.